
Анонимните демографски данни все още могат да се използват за идентификация

Ако сте един от малкото хора, които четат условията за обслужване, може да намерите погребан в политиките за поверителност на различни компании клауза, според който те могат да събират и продават вашите данни на трети страни.
Данните, казват те, са анонимни, но ново проучване, публикувано в Природни комуникации демонстрира, че в зависимост от това, което споделяте, все още може да бъде възможно да ви идентифицирате с удивителна точност. Изследователи от Imperial College London и университета в Louvain в Белгия създадоха модел на машинно обучение, който може да преидентифицира хората от анонимни набори от данни, дори от „силно непълни набори от данни“.
Подобни разкрития идват в момент, в който все повече хора се грижат за компаниите, които продават данните си на трети страни, и имат дразнещи последици за поверителността на съхраняваните (и споделени) анонимни данни, които много компании и академични институции събират и използват.
Как работи анонимизацията на данни?
Освен ако не сте напълно извън мрежата, редовно създавате много лични данни – от онлайн покупките си и маршрутите си до други лични данни, като например вашите здравни записи.
Такива данни са златен прах за рекламодателите, които искат да подобрят насочването си (прочетете: Cambridge Analytica), както и за изследователите, които търсят тенденции в общественото здраве, и да научат разпознаването на лицето на изкуствения интелект.
За да се защитят самоличността зад данните, общите „най-добри практики“ са били премахване на очевидно идентифицираща информация като имена, имейл адреси и телефонни номера и номера на социалното осигуряване..
[Искате повече новини за поверителност и сигурност? Регистрирайте се за бюлетина на ExpressVPN в блога.]
Остарели техники за анонимизация
Много от популярните методи за анонимизация са останали непроменени от 90-те години на миналия век, като не са успели да възприемат по-сложни техники за анонимизация в отговор на експлозията на онлайн данни, тъй като.
Има няколко случая, които се датират още през 2000 г., за анонимни набори от данни, които бяха освободени и впоследствие повторно идентифицирани.
През 2023 г. журналистите успешно „преидентифицират политиците в анонимна база данни на историята на сърфиране на 3 милиона германски граждани, разкривайки медицинската им информация и сексуалните си предпочитания“.
Новото проучване също посочва предишната работа, в която изследователите успяха да „идентифицират по уникален начин хората в анонимни трасета на таксита в Ню Йорк, пътуванията за споделяне на велосипеди в Лондон, данните на метрото в Рига и наборите от данни за мобилни телефони и кредитни карти“.
Малко точки от данни са необходими, за да ви идентифицират
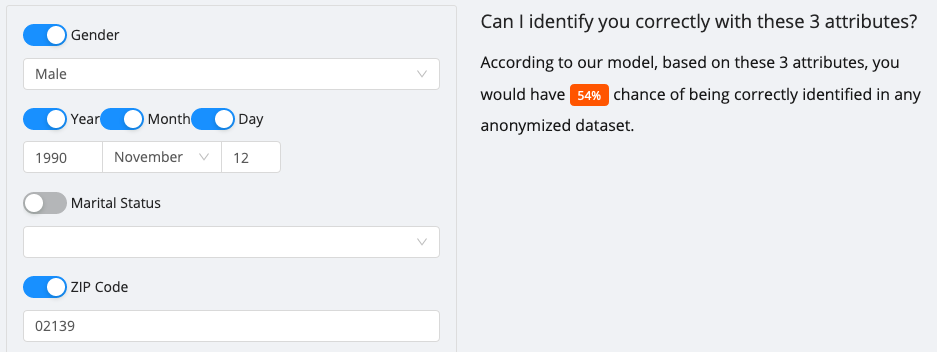
Изследователите, стоящи зад проучването, са изградили онлайн формуляр, в който можете да проверите шансовете си да бъдете идентифицирани (само за жители на САЩ и Великобритания) от хипотетична здравноосигурителна компания с само три точки от данни: вашия пол, дата на раждане и пощенски код.
Например, ако сте били мъж от САЩ, роден на 12 ноември 1990 г. и понастоящем живеете в 02139 пощенски код, има 54% вероятност вашият работодател или съсед може да ви идентифицира.
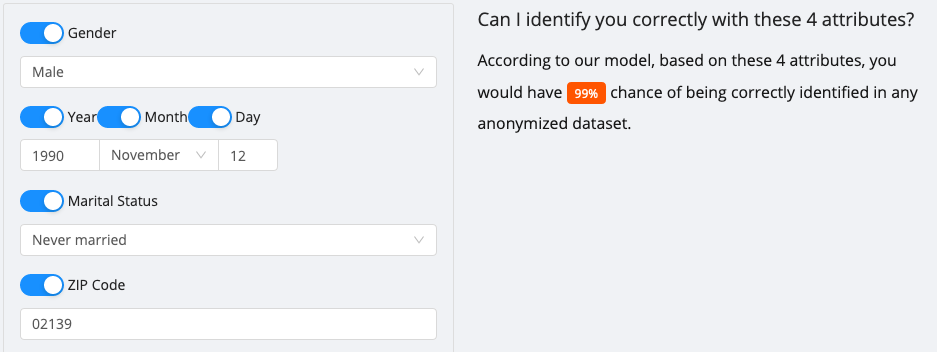
 Но този процент се увеличава, когато добавите още атрибути: Добавянето само на вашето семейно положение може да увеличи шанса да ви идентифицират 99%. Други атрибути включват брой превозни средства, работни класове (избрана индустрия) и собственост на къщата.
Но този процент се увеличава, когато добавите още атрибути: Добавянето само на вашето семейно положение може да увеличи шанса да ви идентифицират 99%. Други атрибути включват брой превозни средства, работни класове (избрана индустрия) и собственост на къщата.
Как компаниите трябва да анонимизират нашите данни?
От това проучване става ясно, че настоящите практики за анонимизация не защитават адекватно личния живот на хората и ги оставят уязвими за преидентифициране от всеки, който има достъп до тези данни.
За съжаление, тук не може да се направи много неща – зависи от компаниите и институциите, които съхраняват, продават и използват тези данни, за да променят начина, по който анонимизират данните. Регламенти като GDPR на ЕС и Закона за поверителност на потребителите в Калифорния изискват лицата във всички набори от данни да бъдат анонимни и невъзможно да бъдат идентифицирани, но държането на компаниите да бъдат отговорни може да се окаже трудно.
Един от начините за предотвратяване на повторна идентификация в анонимни данни е възприемането на диференциална поверителност, математически модел, който внимателно добавя контролирано количество случаен “шум” в данните, преди да бъде изпратен до сървър, като прави данните малко по-приблизителни, отколкото точни, но адекватно защитава поверителността на индивида. Компании като Apple и Google са включили различна поверителност в своето събиране на данни.
Скоро ще видим диференциалната конфиденциалност, подложена на изпитание: тя ще бъде използвана в следващото преброяване на САЩ.
Стъпки, които можете да предприемете, за да се защитите
И така, когато една компания поиска вашето разрешение за споделяне на анонимни данни с трети страни, какво трябва да направите? Помислете сами да анонимизирате данните си. Не всяка компания наистина има право на истинската ви дата на раждане, действителния ви пощенски код, пол или семейно положение или дори задължително истинското ви име. Ако даден детайл не е решаващ за използването на определена услуга, поръсете някои несъответствия наоколо. (И ако в пощенската ви кутия започне да се показва уникално неправилно написано име, ще знаете точно коя компания ви е продала.)
И още по-добре, правите бизнес само с компании, които са напълно авансови за това, какви данни събират, които никога не събират никакви данни, които не се нуждаят, които никога не споделят или продават личната ви информация с която и да е трета страна и които анонимизират дори основна диагностика. информация, смъртоносна сериозно (и дори ви позволяват да се откажете, ако желаете). Случайно знаем поне един.