
Data demografik yang tidak dinamakan masih boleh digunakan untuk mengenal pasti anda

Sekiranya anda salah satu dari beberapa orang yang membaca syarat perkhidmatan, anda mungkin mendapati dikebumikan dalam beberapa polisi privasi syarikat yang menyatakan bahawa mereka boleh mengumpul dan menjual data anda kepada pihak ketiga.
Data yang mereka katakan, tidak dikenali, tetapi kajian baru yang diterbitkan di Komunikasi Alam menunjukkan bahawa, bergantung kepada apa yang anda kongsi, masih boleh dilakukan untuk mengenali semula anda dengan ketepatan yang mengagumkan. Penyelidik dari Imperial College London dan University of Louvain di Belgium mencipta model pembelajaran mesin yang dapat mengenal pasti individu daripada kumpulan data tanpa nama, walaupun dari “kumpulan data yang tidak lengkap.”
Wahyu-wahyu tersebut datang pada masa di mana lebih ramai orang berwaspada terhadap syarikat-syarikat yang menjual data mereka kepada pihak ketiga, dan mempunyai implikasi privasi yang mencemarkan untuk data tanpa nama yang disimpan (dan dikongsi) sekarang yang banyak syarikat dan institusi akademik mengumpul dan menggunakan.
Bagaimanakah penyataan data berfungsi??
Kecuali anda benar-benar di luar grid, anda kerap menghasilkan banyak data peribadi-dari pembelian dalam talian anda dan laluan anda ke lebih banyak data peribadi seperti rekod kesihatan anda.
Tumpuan data sedemikian adalah debu emas untuk pengiklan yang ingin meningkatkan penargetan mereka (baca: Cambridge Analytica), dan untuk para penyelidik yang mencari trend dalam kesihatan awam, dan untuk mengajar pengenalan muka kepada kecerdasan buatan.
Untuk melindungi identiti di belakang data, amalan ‘amalan terbaik’ adalah untuk menghapus jelas mengenal pasti maklumat seperti nama, alamat e-mel, dan nombor telefon dan keselamatan sosial.
[Ingin lebih banyak privasi dan berita keselamatan? Daftar untuk surat berita blog ExpressVPN.]
Teknik anonimasi yang lapuk
Banyak kaedah penyeragaman yang popular tidak berubah sejak tahun 1990-an, gagal mengadopsi teknik-teknik anonimisasi yang lebih kompleks sebagai tindak balas terhadap letupan data dalam talian sejak.
Terdapat beberapa contoh, sejak awal 2000, dari kumpulan dataset yang tidak dikenali yang dibebaskan dan kemudiannya dikenal pasti.
Pada tahun 2023, para wartawan berjaya “mengenal pasti semula ahli politik dalam kumpulan sejarah penyiasatan tanpa nama dari 3 juta rakyat Jerman, mendedahkan maklumat perubatan mereka dan keutamaan seksual mereka.”
Kajian baru itu juga menunjukkan kepada kerja-kerja sebelumnya di mana para penyelidik dapat “mengenali secara unik individu di litar taksi yang tidak dikenali di NYC, perjalanan perkongsian basikal di London, data kereta bawah tanah di Riga, dan data telefon bimbit dan kad kredit.”
Beberapa titik data diperlukan untuk mengenal pasti semula anda
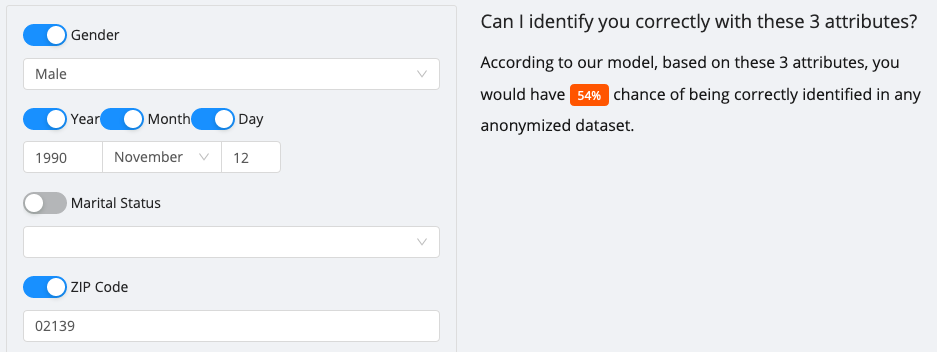
Para penyelidik di belakang kajian itu telah membina satu bentuk dalam talian di mana anda boleh menguji peluang anda untuk dikenal pasti (untuk penduduk A.S. dan UK sahaja) daripada syarikat insurans kesihatan hipotetikal dengan hanya tiga titik data: jantina, tarikh lahir dan kod pos.
Sebagai contoh, jika anda seorang lelaki A.S. yang dilahirkan pada 12 November 1990, dan kini tinggal di kod ZIP 02139, ada satu 54% peluang majikan atau jiran anda boleh mengenal pasti anda.
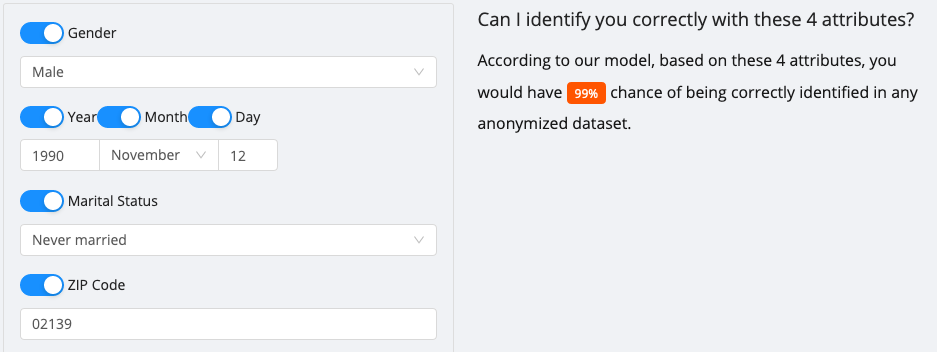
 Tetapi peratusan itu bertambah apabila anda menambah lebih banyak sifat: Menambah status perkahwinan anda sendiri boleh meningkatkan peluang untuk mengenal pasti anda 99%. Ciri-ciri lain termasuk bilangan kenderaan, kelas kerja (industri terpilih), dan pemilikan rumah.
Tetapi peratusan itu bertambah apabila anda menambah lebih banyak sifat: Menambah status perkahwinan anda sendiri boleh meningkatkan peluang untuk mengenal pasti anda 99%. Ciri-ciri lain termasuk bilangan kenderaan, kelas kerja (industri terpilih), dan pemilikan rumah.
Bagaimanakah syarikat harus memberi nama data kami??
Adalah jelas dari kajian ini bahawa amalan pengamalan anonim semasa tidak mencukupi melindungi privasi orang dan meninggalkan mereka terdedah kepada dikenal pasti oleh sesiapa sahaja yang mempunyai akses kepada data tersebut.
Malangnya, tidak banyak yang boleh dilakukan oleh individu di sini-terserah kepada syarikat dan institusi yang menyimpan, menjual, dan menggunakan data ini untuk mengubah cara mereka menamakan data. Peraturan seperti GDPR EU dan Akta Privasi Pengguna California memerlukan kedua-dua individu dalam semua dataset untuk menjadi tanpa nama dan mustahil untuk dikenal pasti semula, tetapi syarikat yang bertanggungjawab boleh membuktikan sukar.
Salah satu cara untuk mencegah pengenalpastian semula dalam data yang tidak dikenali adalah dengan mengamalkan privasi berbeza, model matematik yang dengan teliti menambah jumlah “bunyi bising” yang dikawal dengan teliti ke dalam data sebelum ia dihantar ke pelayan, menjadikan data lebih sedikit daripada tepat, tetapi melindungi privasi individu. Syarikat seperti Apple dan Google telah memasukkan privasi berbeza ke dalam pengumpulan data mereka.
Kami akan melihat kebezaan privasi yang dimasukkan ke dalam ujian dalam masa terdekat: ia akan digunakan dalam banci A.S. yang akan datang.
Langkah yang anda boleh ambil untuk melindungi diri anda
Oleh itu, apabila sebuah syarikat meminta kebenaran anda untuk berkongsi data yang tidak dikenali dengan pihak ketiga, apa yang harus anda lakukan? Pertimbangkan untuk menyiarkan data anda sendiri. Tidak setiap syarikat benar-benar berhak untuk tarikh lahir anda yang sebenar, kod pos sebenar anda, jantina atau status perkahwinan anda, atau semestinya nama sebenar anda. Jika butiran tidak penting untuk penggunaan perkhidmatan tertentu, taburkan beberapa ketidakkonsistenan sekitar. (Dan jika nama salah dijelaskan secara unik muncul dalam peti mel anda, anda akan tahu dengan tepat syarikat mana yang menjual anda.)
Lebih baik lagi, hanya melakukan perniagaan dengan syarikat-syarikat yang benar-benar dimajukan mengenai data yang mereka kumpulkan, yang tidak pernah mengumpul apa-apa data yang mereka tidak perlukan, yang tidak pernah berkongsi atau menjual maklumat peribadi anda dengan mana-mana pihak ketiga, dan yang mengambil tindakan tanpa nama walaupun diagnostik asas maklumat mematikan dengan serius (dan bahkan membenarkan anda memilih keluar, jika anda mahu). Kami tahu sekurang-kurangnya satu.